Point-based、Voxel-based 与 Point-Voxel 融合这三类方法,代表了点云 3D 目标检测领域从“逐点处理”到“体素化高效计算”再到“优势互补”的演进路径。而 PointPillars 以其极致的效率,成为了工业应用中一个重要的里程碑。 我来为您详细介绍这三种主流的3D目标检测方法,以及PointPillars的核心创新。
一、Point-based 方法:PointRCNN

核心思想
直接在原始点云上进行操作,不经过体素化,保留最精细的几何信息。
网络架构
输入点云 → PointNet++编码 → 前景分割 → 点云ROI池化 → 精细化检测
↓
自底向上生成3D候选框
关键创新点
| 模块 | 功能 |
|---|---|
| 自底向上3D候选框生成 | 从分割出的前景点直接生成候选框,避免大量冗余候选 |
| 点云ROI池化 | 将候选框内的点转换到规范坐标系,学习局部空间特征 |
| Bin-based损失 | 将回归问题离散化,提高定位精度 |
优缺点
- ✅ 优点:精度高,保留完整几何细节
- ❌ 缺点:计算量大,推理速度慢(~10 FPS)
二、Voxel-based 方法
2.1 VoxelNet (2017)

核心思想:将点云划分为规则体素网格,转换为类似图像的3D张量处理
点云 → 体素化 → Voxel Feature Encoding(VFE) → 3D卷积 → RPN → 检测结果
VFE层关键设计:
- 每个体素内的点经过PointNet提取局部特征
- 使用Voxel-wise max pooling聚合
- 输出稀疏4D张量 (C, D, H, W)
瓶颈:3D卷积计算量巨大,内存消耗高
2.2 SECOND (2018)

核心改进:稀疏卷积(Sparse Convolution)
| 技术 | 说明 |
|---|---|
| 稀疏卷积 | 仅在非空体素位置计算,跳过空白区域 |
| 稀疏子流形卷积 | 保持稀疏性,避免密度膨胀 |
| VFE简化 | 优化特征编码效率 |
性能提升:相比VoxelNet速度提升 3-5倍,同时保持精度
三、Point-Voxel融合方法:PV-RCNN
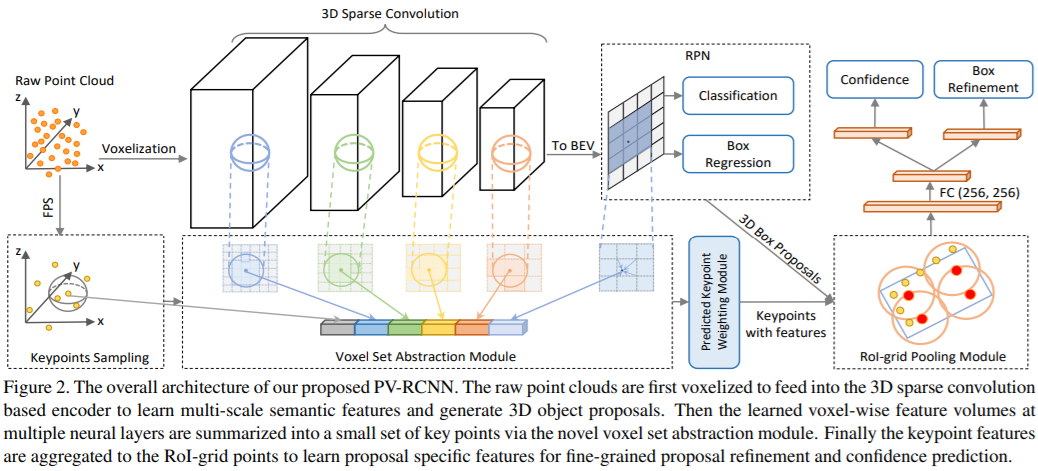
核心思想
“取两者之长”:体素分支提取多尺度语义特征 + 点分支保留精确定位能力
双分支架构
┌─────────────────┐ ┌─────────────────┐
│ Voxel分支 │ │ Point分支 │
│ (3D稀疏卷积) │ ←── │ (原始点云) │
│ 多尺度语义特征 │ │ 精确定位信息 │
└────────┬────────┘ └─────────────────┘
↓
Voxel-to-Point
特征融合 (VSA)
↓
关键点特征聚合
↓
精细化检测头
关键创新:VSA (Voxel Set Abstraction)
# 概念示意
for 关键点 in 原始点云:
# 在多尺度体素特征中查找K近邻
features = []
for scale in [1x, 2x, 4x, 8x]:
voxel_neighbors = find_knn_voxels(keypoint, voxel_features[scale])
features.append(PointNetPool(voxel_neighbors))
# 拼接多尺度特征
keypoint_feature = concat(features)
优势对比
| 方法 | 速度 | 精度 | 核心优势 |
|---|---|---|---|
| PointRCNN | 慢 | 高 | 精细几何 |
| SECOND | 快 | 中 | 高效计算 |
| PV-RCNN | 较快 | 最高 | 语义+几何融合 |
四、PointPillars 的核心创新

PointPillars的核心创新在于它提出了一种全新的、极其高效的点云特征编码器(Pillar Feature Encoder),成功将3D点云检测问题巧妙地转化为一个2D检测问题。
传统方法通常将点云划分为三维立方体(Voxel),计算量随高度维度的增加而显著增长。PointPillars则只在垂直(Z轴)方向上不做切分,而是在XY平面上划分网格,将每个垂直柱体(称为“Pillar”)内的所有点作为处理单元。
其编码器内部流程如下:
- Pillar内部特征提取:每个Pillar内包含多个点,每个点用一个
(x, y, z, r)等向量表示。对每个Pillar,使用一个简化的PointNet(由MLP组成)来学习所有点的特征,并通过最大池化聚合,得到一个代表整个Pillar的固定长度特征向量。 - 生成伪图像(Pseudo-image):将所有Pillar的特征向量根据其原始空间位置重新排列,形成一个形状为
(W, H, C)的伪图像。其中,W和H为XY平面的网格尺寸,C是每个Pillar的特征维度。 - 使用2D CNN进行检测:生成“伪图像”后,就可直接利用成熟的2D CNN(如标准的2D骨干网络和检测头)进行目标检测和3D框回归。
这套设计带来了一个显著的成果——速度极快:其速度可以达到惊人的 62FPS。在实现极高检测速度的同时,PointPillars还能保持非常有竞争力的检测精度。
4.1 核心思想:“伪图像"表示
将3D体素压缩为2D柱状结构(Pillars),彻底消除3D卷积
点云 (x,y,z,r)
↓
┌─────────────────────────────────────┐
│ 划分Pillars (x-y平面网格,z方向无限) │
│ 每个Pillar: 竖直方向的所有点组成一"柱" │
└─────────────────────────────────────┘
↓
PointNet编码每个Pillar → 得到 (C, P) 特征
↓
散射到2D伪图像 (C, H, W) ←── 关键创新!
↓
标准2D CNN (ResNet/FPN) → SSD检测头
4.2 三大核心创新
| 创新点 | 具体设计 | 效果 |
|---|---|---|
| 1. Pillar特征编码 | 用简化PointNet学习每个竖直柱的特征,代替3D卷积 | 计算量骤降 |
| 2. 伪图像散射 | 将不规则点云转换为规则2D张量,可用成熟2D CNN | 速度极快 |
| 3. 全2D流水线 | 从特征提取到检测头全部使用2D操作 | 62 FPS (Titan X) |
4.3 为什么这么快?
VoxelNet/SECOND: 3D稀疏卷积 → 计算复杂度高 → ~20 FPS
PointPillars: 2D标准卷积 → 高度优化成熟 → ~62 FPS
↑
精度损失<1% mAP,速度提升3倍!
4.4 网络结构可视化
输入点云 [N, 4] (x,y,z,r)
│
▼
┌─────────────┐ ┌─────────────────┐
│ Pillar编码 │───→ │ 线性层+BN+ReLU │
│(简化PointNet)│ │ MaxPool │
│ [N, 64] │ │ [P, 64] │
└─────────────┘ └─────────────────┘
│
▼ 散射到网格
伪图像 [64, H, W]
│
▼
┌─────────────┐
│ 2D Backbone │──→ FPN多尺度特征
│ (ResNet) │
└─────────────┘
│
▼
SSD检测头 → 3D框 (x,y,z,w,l,h,θ)
4.5 精度-速度权衡
| 数据集 (KITTI) | Easy | Moderate | Hard | 速度 |
|---|---|---|---|---|
| PointPillars | 86.10 | 76.97 | 74.02 | 62 FPS |
| SECOND | 87.43 | 76.48 | 69.10 | 20 FPS |
| PointRCNN | 88.88 | 78.63 | 77.38 | 10 FPS |
结论:PointPillars以极小的精度损失换取了巨大的速度提升,成为工业部署的首选基线方法。
五、方法演进总结
2017 VoxelNet ——→ 2018 SECOND ——→ 2019 PointPillars
│ │ │
体素化+3D卷积 稀疏3D卷积 2D伪图像
(慢但有效) (快些) (极快!)
2019 PointRCNN ——→ 2020 PV-RCNN
│ │
纯点云处理 体素+点云融合
(精度高) (精度最高)
工业界选择建议:
- 实时性优先 → PointPillars / SECOND
- 精度优先 → PV-RCNN / PointRCNN++
- 平衡方案 → CenterPoint (基于PointPillars的改进)
六、三种主流3D目标检测方法对比
这三种方法的核心区别在于它们处理点云数据的方式不同,这也决定了各自的优劣势。
| 方法类别 | 核心思想 | 代表算法 | 优点 | 缺点 |
|---|---|---|---|---|
| Point-based | 直接处理原始点云,使用PointNet++等网络提取逐点特征,最大程度保留几何信息。 | PointRCNN | 几何信息保留完整:能捕捉精细的局部结构,检测精度潜力高。 | 计算开销大:邻域搜索和特征聚合耗时长,难以满足实时性要求[reference:1]。 |
| Voxel-based | 将点云划分为规则的3D网格(体素),在体素内进行特征提取,将不规则数据转为规则表示。 | VoxelNet, SECOND | 计算高效:规则化的3D网格便于使用3D卷积,利于并行加速。 | 量化信息损失:体素化过程会损失部分几何细节,且计算量与体素分辨率立方级相关。 |
| Point-Voxel融合 | 结合两者优势,在体素分支高效编码全局上下文,同时保留关键点特征进行精细的局部信息聚合。 | PV-RCNN | 精度与效率的平衡:在保持较高检测精度的同时,计算效率优于纯Point-based方法。 | 网络结构复杂:涉及多个分支和复杂的特征交互,设计和调优难度更大。 |
1. Point-based方法代表:PointRCNN
PointRCNN 是一个两阶段(Two-stage)的检测框架,其核心是“先分割,后优化”,更好地保留了原始点云的细节。
第一阶段:自底向上的3D候选框生成 网络首先为每个点预测一个“前景/背景”的语义标签(Segmentation),然后直接基于所有预测为前景的点生成3D候选框。这种方式能从点云中生成少量高质量的3D候选框,避免了传统方法中将点云投影到图像或鸟瞰图时的信息损失。
第二阶段:点云区域池化与框优化 第一阶段生成的候选框精度有限,第二阶段进行精炼。它将每个候选框内的点云坐标转换到标准坐标系(Canonical Coordinates),与第一阶段学习到的全局语义特征结合,利用PointNet-like网络学习更好的局部空间特征,最终得到更精确的3D框和置信度得分。
2. Voxel-based方法代表:VoxelNet 与 SECOND
VoxelNet 开创了“体素化”处理点云的范式,而 SECOND 在其基础上引入了稀疏卷积,极大地提升了计算效率。
VoxelNet:开创体素处理范式 VoxelNet 是一个统一的单阶段(Single-stage)端到端网络。
- 核心思想:将点云划分为等间距的3D体素,并使用堆叠的体素特征编码(Voxel Feature Encoding, VFE)层来提取特征。
- 技术细节:VFE层通过体素内逐点MLP和局部最大池化,聚合体素内所有点的特征来表征局部形状。之后,使用3D CNN进一步聚合邻域体素特征,扩大感受野,最后由区域提议网络(RPN)输出检测结果。
SECOND:引入稀疏卷积加速 SECOND 的主要贡献是引入了稀疏3D卷积。因为在VoxelNet的3D CNN中,绝大多数体素都是空的(稀疏性),计算这些空区域会浪费大量资源。稀疏卷积只对有非空点体素进行卷积运算,极大地减少了计算量和内存占用,实现了更快的训练和推理。此外,它还采用了角度损失(Angle Loss) 来更好地回归物体的朝向角。
3. Point-Voxel融合方法代表:PV-RCNN
PV-RCNN 由同一作者在PointRCNN之后提出,旨在融合两类方法的优势,实现性能突破。
核心思想:深度融合3D体素CNN(高效)和基于PointNet的集合抽象(精细),利用两者优势学习更具判别力的点云特征[reference:20]。
创新模块:
- 体素到关键点场景编码:通过3D体素CNN高效编码场景,并将其提炼到少量关键点中,大幅降低后续计算量。
- RoI网格池化:为每个候选框定义一组网格点,并从之前提炼出的关键点中,通过多感受野的集合抽象来聚合该网格点的特征,为框的精炼提供了丰富的上下文信息。